
Yelp 拥有超过 1 亿张由用户生成的照片,这些照片从晚餐、理发,到我们最新的功能之一:yelfies。这些图像占据了用户 APP 和网站的大部分带宽,这意味着存储和传输的巨大成本。为了向用户提供最好的体验,我们努力优化这些图片并将其平均大小缩小了 30%。这样节省了用户的时间和带宽,并降低了为这些图像提供服务的成本。哦,我们这样做都没有降低图像的质量呢!

背景
Yelp 已经帮用户存储上传的照片超过 12 年了。我们那些将无损格式的图片(PNG,GIF)保存成 PNG 格式,而所有其他的格式的图片则保存成 JPEG 格式。我们保存图片用的是 Python 和 Pillow,并使用如下代码片段,开启了我们照片上传的故事:
# do a typical thumbnail, preserving aspect ratio
new_photo = photo.copy()
new_photo.thumbnail(
(width, height),
resample=PIL.Image.ANTIALIAS,
)
thumbfile = cStringIO.StringIO()
save_args = {‘format’: format}
if format == ‘JPEG’:
save_args[‘quality’] = 85
new_photo.save(thumbfile, **save_args)
以此作为起点,我们开始研究潜在的文件大小优化方法,可以让我们在不损失质量的前提下使用。
优化
首先,我们不得不决定是自己来处理这个问题,还是让 CDN 提供商用他们的魔力来神奇地改变我们的照片。在优先保证高质量的内容前提下,去评估众多选项并使得潜在的尺寸与质量相互抵消是有意义的。我们先行调查了当前照片文件大小缩小的现状 – 可以做出什么改变,以及与每个改变相关联的大小/质量下降。随着这项调查的完成,我们决定从三大类方法来着手。这篇文章剩下的部分解释了我们做了什么,并在每项优化中获得了多少收益。
1.Pillow中的改变
- 优化标志
- 渐进的JPEG
2.应用照片逻辑的更改
- 大型 PNG 格式图的检测
- 动态 JPEG 质量
3.JPEG编码器更改
- Mozjpeg(网格量化,自定义量化矩阵)
Pillow 中的改变
标志位优化
这是我们最简单的更改之一:启用 Pillow 中的设置,以 CPU 耗时为代价(optimize = True)来节约更多的文件大小。 由于该权衡的本质,这样做并不会影响图像质量。
对于 JPEG 格式的图片,该标志位会指示编码器,通过扫描每张图片做一次附加的遍历,来找到最佳霍夫曼编码。对每张图片的第一遍扫描,我们不是写入文件,而是计算每个值的出现统计,这是计算理想编码所需要信息。PNG 内部使用 zlib,因此在这种情况下,标志位优化能有效地指示编码器使用 gzip -9,而不是 gzip -6。
这是一项简单的改进,但事实证明它并非灵丹妙药,只减少百分之几的文件大小。
渐进式 JPEG
将图像保存为 JPEG 格式时,你可以选择几种不同的类型:
- 从上到下加载的 JPEG 标准图像。
- 渐进式 JPEG 图像,从较模糊加载到较不模糊。Pillow(progressive = True)可以轻松地启用渐进式选项。 因而,人类肉眼可感知到性能有了提升(也就是说,当图像部分缺失时,更容易注意到它不是完全锐利的)。
此外,渐进式文件打包方式通常会使得文件尺寸减少。如维基百科文章中所详尽解释的那样,JPEG 格式在 8×8 像素块上使用 Z 字形模式进行熵编码。当这些像素块的值被解包并按顺序排列时,我们通常首先得到的是非零数字,然后是 0 的序列,用该模式对于图像中的每个 8×8 块进行重复和交织。在使用渐进编码时,解开的像素块的顺序发生了改变。每个块值较高的数字会首先出现文件中(它给出了渐进式图像最早扫描到的不同阻塞),并且那些能增加出色细节的小数字(包括更多的 0),它们的跨度将更长,并一直持续到末位。图像数据的这种重新排序不会改变图像本身,而是增加了在一行中的可能存在的 0 的数量(这样可以更容易地压缩)。
与由用户贡献的美味甜甜圈图像做比较(点击查看大图):

(1)标准 JPEG 格式图渲染的模拟

(2)渐进式 JPEG 格式图渲染的模拟。
应用照片逻辑的改变
大型 PNG 格式图片的检测
Yelp 为用户生成的内容提供了两种图像格式 – JPEG 和 PNG。JPEG 是一种很好的照片格式,但通常会与高对比度设计内容(如 logo)相结合。相比之下,PNG 是完全无损的,非常适合图形,但对于那些小失真不可见的照片来说占用的空间太大了。在用户上传实际照片是 PNG 格式的情况下,我们识别这些文件并将其另存为 JPEG 格式,可节省下大量的存储空间。Yelp 上一些常见的 PNG 照片来源于移动设备由和应用程序拍摄的截图,这些照片是通过添加特效或边框修饰了的。
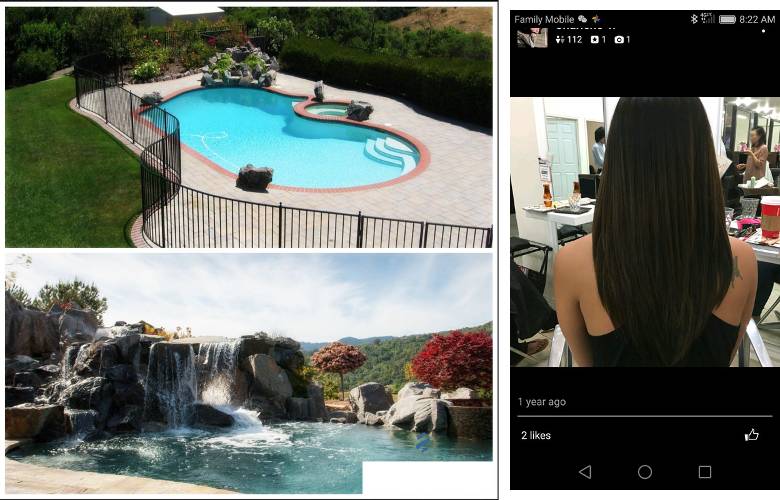
(左)一个典型的具有 logo 和边框的复合 PNG 格式的上传图。 (右)一个典型的来自于屏幕截图的 PNG 格式的上传图。
我们想减少这些不必要的 PNG 格式的图片数量,但重要的是要避免矫枉过正或降低了 logo 和图形等的质量。我们应该如何区分出一张图片中属于照片的部分呢?从像素层面可以做到吗?
使用了 2500 张图片作为实验样本后,我们发现文件大小和独特像素的结合可以很好地区分照片。我们用我们最大的分辨率生成候选缩略图,看看输出PNG文件是否大于 300 KiB。如果是,我们还将检查图像内容,查看是否有超过 2^16 种独特颜色(Yelp 将 RGBA 格式的上传图片转成 RGB 格式,但如果没这样做的话,我们也会检查)。
在实验数据集中,那些手动调整阈值来定义成“ bigness ”占了有可能缩小的文件大小的 88%(即如果我们要转换所有图像,我们预期的文件大小的缩小),这是在不会导致转换后图形的任何假阳性的前提下进行的。
动态的 JPEG 质量
缩小 JPEG 文件大小的第一个也是最为人所知的一种方式是称为质量的设置。许多能保存 JPEG 格式图片的应用程序会将质量指定为一个数字。
质量这个词有点抽象。事实上,一幅 JPEG 格式的图像的每个颜色通道都有单独的质量。质量等级从 0 到 100 映射到颜色通道的不同量化表,取决于丢失了多少数据(通常是高频成分)。信号域中的量化是 JPEG 编码过程中丢失信息的步骤之一。
减小文件大小的最简单的方法是降低图像的质量,这会引入更多的噪声。不是每张图片在一个给定的相同质量水平上都会丢失相同的信息量。
我们可以为每张图片动态地选择一种质量优化设置,找到质量和存储大小之间的理想平衡。有两种方法可以做到这一点:
- 自下而上:这些是通过处理 8 x 8 像素块级别的图像生成调谐量化表的算法。它们计算出丢失了多少理论上的质量,以及丢失的数据如何放大或消除,对人眼可见失真的多或少。
- 自上而下的:这些算法是将整张图片与其原始无失真版本进行比较,检测丢失了多少信息。通过迭代生成具有不同质量设置的候选图像,我们可以选择其中一张图片,作为满足某种评估算法的最低评估水平的图像。
我们评估了一种自下而上的算法,在实验中,在我们希望使用的质量范围的上限内没有产生合适的结果(尽管它似乎仍然具有中档图像质量的潜力, 这时编码器可以开始更冒险地去丢弃它的字节)。关于这一策略的众多学术论文在90年代初就有发表,该方法对计算能力要求很高,并且走了选项 B 地址这类的捷径,例如不评估块之间的交互。
所以我们采取了第二种方法:使用对分的算法生成不同质量水平的候选图像,并通过使用 pyssim 函数来计算其结构相似性度量(SSIM),来评估每个候选图像的质量下降,直到该值处于可配置但阈值也还处于静态。这允许我们选择性地降低文件的平均大小(和平均质量),仅仅针对那些已经开始产生肉眼可识别的质量下降的图像。
在下图中,我们绘制了用3种不同质量方法生成的 2500 张图像的SSIM值的表。
1、用一种质量为 85 的初始方法作出原始图像,使用蓝线来绘制。
2、一种能降低文件大小,质量改为 80 的替代方法,用红线来绘制。
3、我们在最后选用了一种方法,使用橙色绘制动态质量的 SSIM 为 80 – 85 的图,即选择质量为 80 到 85(含)的图像,这是基于一种满足或超过的 SSIM 比率:该比率是预先计算的、使转换发生在图像范围中间的某个静态值。这样我们可以降低文件的平均大小,而不会降低那些质量最差的图片的质量。
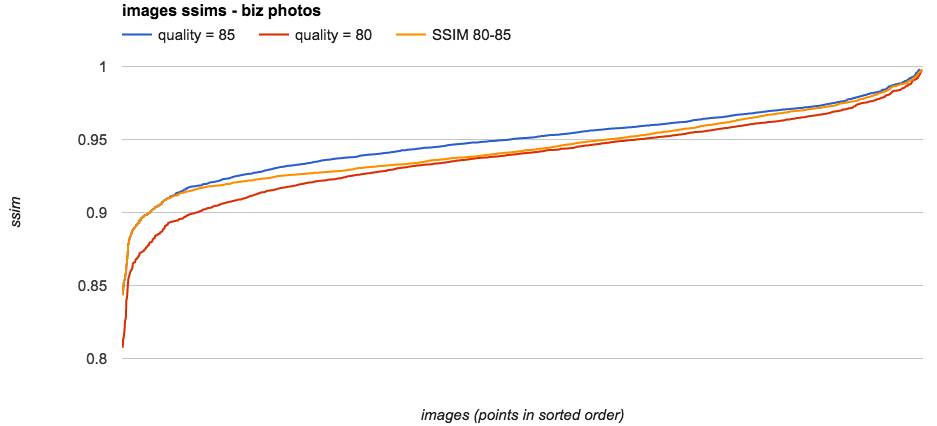
3 种不同质量策略下 2500 张图片的 SSIM 值图
SSIM?
有不少图像质量算法试图模仿人类视觉系统。我们已经评估过其中的许多算法,并认为 SSIM 虽然较为古老,但基于以下几个特征是最适合于迭代优化的:
1、对 JPEG 量化误差敏感
2、快速,简单的算法
3、可以直接对 PIL 原生图像对象进行计算,而不是将图像转换为 PNG 格式并将其传递给 CLI 应用程序(参见#2)
动态质量的代码示例:
import cStringIO
import PIL.Image
from ssim import compute_ssim
def get_ssim_at_quality(photo, quality):
“””Return the ssim for this JPEG image saved at the specified quality”””
ssim_photo = cStringIO.StringIO()
# optimize is omitted here as it doesn’t affect
# quality but requires additional memory and cpu
photo.save(ssim_photo, format=“JPEG”, quality=quality, progressive=True)
ssim_photo.seek(0)
ssim_score = compute_ssim(photo, PIL.Image.open(ssim_photo))
return ssim_score
def _ssim_iteration_count(lo, hi):
“””Return the depth of the binary search tree for this range”””
if lo >= hi:
return 0
else:
return int(log(hi – lo, 2)) + 1
def jpeg_dynamic_quality(original_photo):
“””Return an integer representing the quality that this JPEG image should be
saved at to attain the quality threshold specified for this photo class.
Args:
original_photo – a prepared PIL JPEG image (only JPEG is supported)
“””
ssim_goal = 0.95
hi = 85
lo = 80
# working on a smaller size image doesn’t give worse results but is faster
# changing this value requires updating the calculated thresholds
photo = original_photo.resize((400, 400))
if not _should_use_dynamic_quality():
default_ssim = get_ssim_at_quality(photo, hi)
return hi, default_ssim
# 95 is the highest useful value for JPEG. Higher values cause different behavior
# Used to establish the image’s intrinsic ssim without encoder artifacts
normalized_ssim = get_ssim_at_quality(photo, 95)
selected_quality = selected_ssim = None
# loop bisection. ssim function increases monotonically so this will converge
for i in xrange(_ssim_iteration_count(lo, hi)):
curr_quality = (lo + hi) // 2
curr_ssim = get_ssim_at_quality(photo, curr_quality)
ssim_ratio = curr_ssim / normalized_ssim
if ssim_ratio >= ssim_goal:
# continue to check whether a lower quality level also exceeds the goal
selected_quality = curr_quality
selected_ssim = curr_ssim
hi = curr_quality
else:
lo = curr_quality
if selected_quality:
return selected_quality, selected_ssim
else:
default_ssim = get_ssim_at_quality(photo, hi)
return hi, default_ssim
还有一些关于这种技术的其他博客文章,这里是柯尔特·麦卡尼斯(Colt Mcanlis)的一篇博文。当我们发布这篇博客的时候,Etsy 已经发表了一篇了!击掌吧,更快的网络!
JPEG 编码器的更改
Mozjpeg 是 libjpeg-turbo 的一个开源分支,它采取以时间换空间的方法,通过更长时间的运算换取更加优化的文件尺寸。这种方法很好地与离线批处理方法结合以重新生成图像。一些更昂贵的算法用了比 libjpeg-turbo 多出 3 – 5 倍的时间,使得图像更小了一些!
mozjpeg 的区别之一是使用一种替代量化表。如上所述,质量是用于每个颜色通道的量化表的抽象。所有符号都指向默认的 JPEG 量化表,因而它很容易被击败。用这个词来说,
JPEG spec:
这些表仅作为示例,并不一定适用于任何特定应用。
那么自然地,不要惊讶于你知道这些表是大多数编码器使用的默认值…
Mozjpeg 经历了为我们的替代表做基准测试的麻烦时期,并在之后成为了它所创建的图像中,能用到的性能最好的通用替代品。
Mozjpeg + Pillow
大多数的 Linux 发行版都默认安装了 libjpeg。所以在 Pillow 下使用 mozjpeg 在默认情况下不起作用,但配置起来也不是很困难。当您构建 mozjpeg 时,请使用–with-jpeg8 标志位,并确保可以通过 Pillow 链接到它。如果您使用Docker,您可能会有一个 Dockerfile,如:
FROM ubuntu:xenial
RUN apt–get update
&& DEBIAN_FRONTEND=noninteractive apt–get –y —no–install–recommends install
# build tools
nasm
build–essential
autoconf
automake
libtool
pkg–config
# python tools
python
python–dev
python–pip
python–setuptools
# cleanup
&& apt–get clean
&& rm –rf /var/lib/apt/lists/* /tmp/* /var/tmp/*
# Download and compile mozjpeg
ADD https://github.com/mozilla/mozjpeg/archive/v3.2-pre.tar.gz /mozjpeg-src/v3.2-pre.tar.gz
RUN tar –xzf /mozjpeg–src/v3.2–pre.tar.gz –C /mozjpeg–src/
WORKDIR /mozjpeg–src/mozjpeg–3.2–pre
RUN autoreconf –fiv
&& ./configure —with–jpeg8
&& make install prefix=/usr libdir=/usr/lib64
RUN echo “/usr/lib64n” > /etc/ld.so.conf.d/mozjpeg.conf
RUN ldconfig
# Build Pillow
RUN pip install virtualenv
&& virtualenv /virtualenv_run
&& /virtualenv_run/bin/pip install —upgrade pip
&& /virtualenv_run/bin/pip install —no–binary=:all: Pillow==4.0.0
以上!使用它,您将可以在正常图片工作流程中,使用由 mozjpeg 支持的 Pillow。
影响
这些改进中的每一项对我们的提升分别是多少呢?我们随机抽取 2,500 张 Yelp 上的商业照片开始了此项研究,测试照片大小在经过我们的处理流程后有怎样的变化。
1、通过改变 Pillow 的设置,可以将图片大小减小 4.5%
2、大型 PNG 格式图片检测可以将图片大小减小 6.2%
3、动态质量可以将图片大小减小 4.5%
4、切换到 mozjpeg 编码器可以将图片大小减小 13.8%
这些改进使得图像文件的平均大小减少了约 30%,并被我们应用到我们最大和最常见的图像分辨率上,使网站能为用户提供更快速的服务,并且每天在数据传输上节省了 TB 级别的容量。按照 CDN 来衡量:
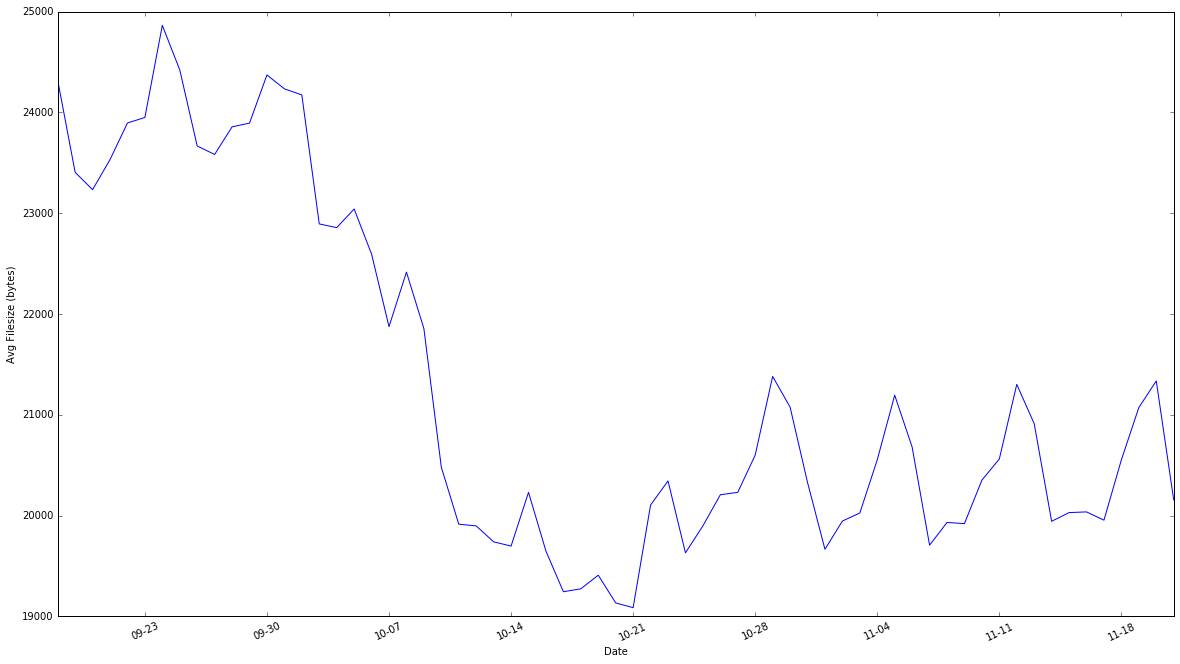
从 CDN(结合非图像静态内容)测量的平均文件大小。
我们还没做的
本节旨在向您介绍可能能够做出的一些常见改进,有的是因为它们和 Yelp 使用的工具并无关系,有些是因为我们权衡后决定不做。
子采样
子采样是决定网页图像的质量和文件大小的主要因素。对于子抽样的更详尽的描述可以在网上找到,但在这个博客文章我们只要说以 4:1:1(这是 Pillow 的默认值,没有指定任何其他内容)进行子采样就够了,所以我们无法了解能进一步缩小多少。
有损的 PNG 编码
在了解我们对 PNG 格式图片做了什么之后,用例如 pngmini 这样的有损编码器,选择将这些图片中一部分保留为 PNG 格式,可能是有意义的,但是我们选择将其重新保存成 JPEG 格式。这是一个结果看来合理的替代选项,根据作者的说法,未修改的 PNG 格式图片的文件大小缩小了 72-85 %。
动态内容类型
为更多的现代化内容类型提供支持,如 WebP 或 JPEG2k 肯定是我们的未来要做的。而一旦这个假设的项目实行了,就会有大量的用户要求为现有已优化的 JPEG / PNG 图像做这些,这将继续使该项工作非常值得做。
SVG
我们在网站上的许多地方使用 SVG,就像我们设计师创建的静态资产,这已成为我们的指导风格。虽然这种格式和优化工具(如 svgo)有助于减少网站页面的开销,但它与我们在这里所做的工作无关。
供应商的魔术
能提供图像传送/调整大小/裁剪/转码服务的供应商太多,包括开源的 thumbor。也许这是支持响应式图像,动态内容类型的最简单方法,并且在将来仍然能让我们保持在技术前沿。而现在我们的解决方案仍然是独立的。
拓展阅读
这里列出的两本书在这个领域历史上是绝对能站稳脚跟的,强烈建议您进一步阅读这些书籍。
- High Performance Images
- Designing for Performance

- 随机文章
标签云集
-
图标设计
jupyter
APP设计参考
python插件
JavaScript小技巧
docker的使用
vue
linux
react
APP UI设计
nginx
vue小技巧
iphone x
MySQL小知识
Java
交互设计
ui设计
php
数据库
mysql优化
移动端识别
app设计
前端开发
javascript
大数据可视化
golang小技巧
Redis
css
k8s
分布式
ios
mysql
logo
electron开发
前端技术
网页设计
adobe
docker
PHP小技巧
python
android
设计灵感
zabbix
swoole
webpack
树莓派
设计教程
页面设计
docker小技巧
docker命令


